
RAG Model with Spring AI
- Anand Nerurkar
- Sep 15, 2024
- 3 min read

RAG (Retrieval Augmented Generation )
===

Normally LLM data is trained for genric one and gives old/stale data upto june 21, when we want specific data , from specific source ,in specified context, then we make use of RAG.

For Ex: T20 world cup details , who won it , India won T20 world cup, this data is not available with LLM as it is not being trained or fed with current data.
so we can use RAG Model with the current data, pass on to LLM model with the context ,query and prompt so that LLM model return latest updated data. thus it enhances user trust.
IT is cost efficient as creating LLM model is expensive , so we can use existing LLM model + RAG Model with context to provide accurate , current latest data.
How to build RAG Model in application - this is where we provide source of truth= external data like file system or database or Vector Database.

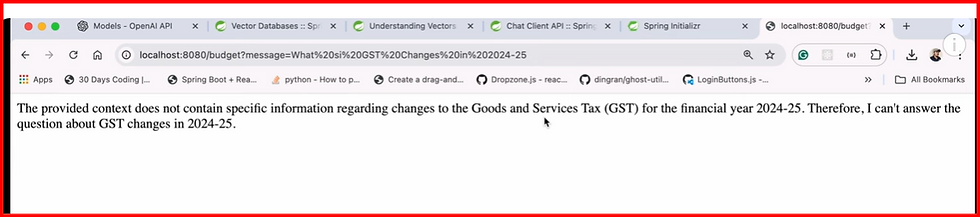
UseCase1 : Budget information for 24-25. We will update LLM model with RAG Model feeds with budegt 24-25 info. So LLM model can give accurate data for the budeht upto 24-25. IF we ask any other budget info beyond 24-25, then we will get message accrodingly.
Let us develop budget application with spring ai + openAI model. Open AI model is updated upto dec 23 data, but not for 24.
our budget is being done on july 24, this data we need to feed to our openAI LLM model with relevant context and get this LLM model.
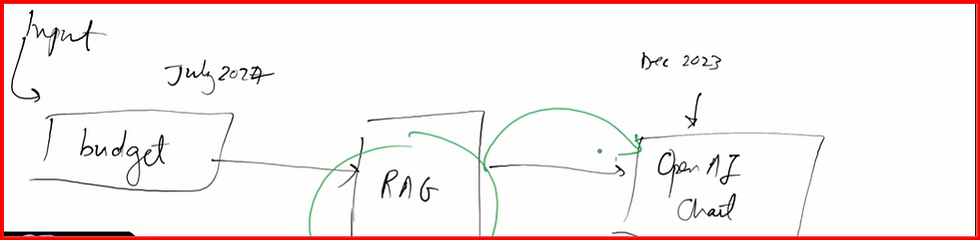
For RAG Model, we will use SimpleVectorStore- Vector Database
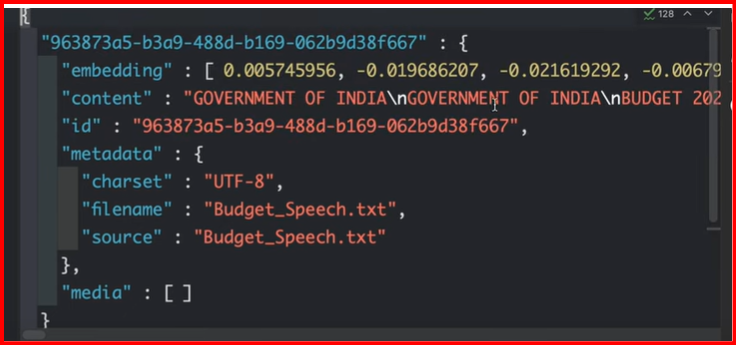
we will make use of budget speech text file for year 2024 , and with help of simplevectorstore-jsonbased store ,convert this to vectorstore. This is one time process. So initially we will check if vectorstore file exist, if not then convert text to vectorstore.


import org.springframework.ai.document.Document;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.reader.TextReader;
import org.springframework.ai.transformer.splitter.TextSplitter;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.ai.vectorstore.SimpleVectorStore;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.Resource;
import java.io.File;
import java.util.List;
@Configuration
public class Config {
@Value("classpath:/Budget_Speech.txt")
private Resource budget;
@Bean
SimpleVectorStore simpleVectorStore(EmbeddingModel embeddingModel) {
SimpleVectorStore vectorStore
= new SimpleVectorStore(embeddingModel);
File vectorStoreFile =
new File("/downloads/budget-ai/src/main/resources/vector_store.json");
if(vectorStoreFile.exists()) {
System.out.println("Loaded Vector Store File!");
vectorStore.load(vectorStoreFile);
} else {
System.out.println("Create Vector File");
TextReader textReader = new TextReader(budget);
textReader.getCustomMetadata()
.put("filename", "Budget_Speech.txt");
List<Document> documents = textReader.get();
TextSplitter textSplitter = new TokenTextSplitter();
List<Document> splitDocuments = textSplitter.apply(documents);
vectorStore.add(documents);
vectorStore.save(vectorStoreFile);
}
return vectorStore;
}
}
run application and vector store file is created as below
budget controller-rest endpoint
==
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.QuestionAnswerAdvisor;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class BudgetController {
private ChatClient chatClient;
public BudgetController(ChatClient.Builder builder,
VectorStore vectorStore) {
this.chatClient = builder
.defaultAdvisors(new QuestionAnswerAdvisor(vectorStore,
SearchRequest.defaults()))
.build();
}
@GetMapping("/budget")
public String budgetQandA(@RequestParam(value = "message",
defaultValue = "What is the Highlight of the Budget 2024-25")
String message) {
return chatClient
.prompt()
.user(message)
.call()
.content();
}

hit endpoint and output is


UseCase2- Indian Constitution with latest update till 24-25. so we will download the IC -pdf file and store it in Postgress Vector DB. So instead of firing OpenAI API directly, first we will refer the context with RAG in between , then pass that info to openAI so that it understand the context and return accurate data.



Comments