
Kafka
- Anand Nerurkar
- Oct 24, 2023
- 4 min read

Updated: Oct 25, 2023
dfsfsfsfsf




To share data, we may have to set up data pipeline which may be complex





Kafka Architecture





if we want to send all records of a table to kafka, each row will be message for kafka

Similalry for a text file to send, each line of file will be message for a kafka







we need to do partition size estimation based on requirements, kafka wont decide it. This is Architectural decision.

Kafka Partition Rule of Thumb
==





Why Consumer Group
==
Consider below usecase

In above , we have various billing app in retail organizatin, that want to send billing info to data center, so we make use of KAfka cluster to exchange data. These data will be consumed by a consumer and will process the data and update it to datacenter. But in this case we have only one cosumer, various billing app-producer, so performance will be low. To increase the performance , we can create a comsu,er group - collection of consumer,each cosumer will be assigned a partition from a topic so that all partition data can be consumed parallet, increasing performance and throughput.

Partitioning and consumer group is a tool for scalability. Please note that max no of consumers in a consumer group is the total no of partition you ave on a topic.

How to make it fault tolerance--- by maintinaing multiple copy of data on different broker.This is where we need to configure replication factor.
Replication factor of 3 mean maintining 3 copy of data on 3 brokers.

How Kafka implement above mechanism for replication factor
--
it follows Leader follower pattern. once of the broker is assigned as leader , remaining broker as follower.

we need 3 node broker cluster to set up in above cases for replication factor of 3.

server1.properties
==

brokerid=1,port=9093 ,kafka-log1 for 2nd broker,2 f,port=9094 ,kafka-log2 for 3rd broker

server2.properties
==
brokerid=2 ,port=9094 ,kafka-log2 for 3rd broker
Broker Configuration
===

Callback & Acknoledgement
===
Fire & Forget - used for non critical message flow like twitter read,youtube/facebook likes etc
synchronous send -- wait for success or failure, limited throughput, logging error for later anaylysis in case of error,n/w delay
asynchronous send- in this we send msg and register a callabck to receive acknowledgement


Custom Partitioner
===
Sensor data to be pushed to topic, topic having 10 oartition, we need tss sensor data to be pushed to 3 partition and remaining 7 partition for other sensor data, this is where we will use custom partitioner.


Consumer Group
===

In a consumer group, there will be multiple consumer, which will reading messages from a topic, so there is a chance of reading message duplicate .but this is not possible b/c kafka internally assigneach partion to different consumer in consumer group.



In short, consumer do not share a partition. Normally no of partition =no of consumer in consumer group. Even if it has more consumer than 4 partition, then only 4 consumer can be active ,remaining will be idle.
consumer join the group or exit the group, so we may need to rebalance the partition assignment activity. This is taken care by below



Current offset-Initially current offset is at 0 , as producer keep pushing messages to topic-partition, offset keep increasing by 1. Next time when message is pushed again it will start appending messages from the current offset position.
Commited offset--- Once we process the messages, we need to commit those messages. once commited, then commited offset will indicate that location so that there is no duplicate processing of messages.
how to commit

default is true for enable.auto.commit
default interval 5 sec
default option is costing a lot in terms of performance. Unless 5 sec interval pass, it wont commit messages and if rebalancing happens thenthose message may get assigned to other consumer, which will again proces the messages. To prevent this problem, we make use manual commit.
Manual Commit
commit synch --- reliable,retry in case of error but blocking method
commit asynch--will send msg and continue,no retry mechanism

In above case-commit asynch- let us say commit offset at 75 failed, waiting for retry for recoverable , now we have commit offset at 100 which is higher than 75, it already commited msg upto commit offset 100. so manual commit is more controlled and reliable.
how to commit a particular offset
===



Kafka take care of partition assignment to consumer. This is default automatic partition assignment,but sometime we need control on this for certain use cases so that we can assign the partition to consumers.
Schema Evolution
====
Avro is the data serilization/deserilization techniques that offer

Please consider below avro schema

generate code for schema with avro tool as below







producdr code with kafkaavroserilizer

consumer code with kafkaavrodeserilizer
--

we will make use of confluent platform for the above use case.
doanload and install confluent
start zookeeper
start kafka
start schema registry
thus we can make use of schema registry and kafkaavroserilizer/deserilizer for shcema evolution chnages and support both old and new producer and cosumer.
With Springboot, we need to include confluent dependency as below

to generate avro java class,include plugin as below in pom.xml
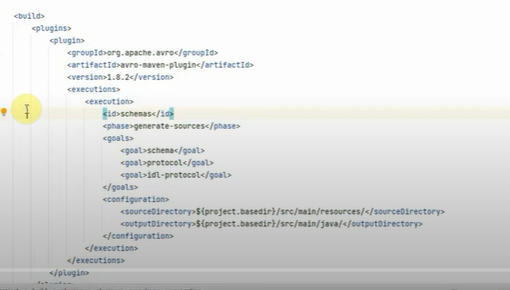

producer/avroschema file
==

producer-application.yml for schema registry

producer-service class with kafkatemplate to send message
==

restcontoller to send message
==

postman post req
==

consumer code
==

Kafka with SpringBoot
====
Instalation
==
download kafka
unzip it
use producer console to create publisher and send message to kafka
use consumer console to create consumer and consume message
Below is the location where kafka is downloaded and extracted

goto bin and open cmd prompt and issue below coomand
To start zookeeper

To start kafka server
open other cmd prompt and issue below command

we will make use of kafka console to create topic,producer and consumer

we will use kafka-topic.bat to create topic as below

write some events into topic
==


Consumer will subscribe this topic and consume message



multiconsumer
==


UseCase 1
==

springboot Application 1-Producer-Publisher



Kafka Configuration
==


Consumer Application
===




consumer console
==




Comments