
Hibernate Interview Questions
- Anand Nerurkar
- May 1, 2024
- 12 min read

What is the difference between openSession and getCurrentSession?
This getCurrentSession() method returns the session bound to the context and for this to work, you need to configure it in Hibernate configuration file. Since this session object belongs to the context of Hibernate, it is okay if you don’t close it. Once the SessionFactory is closed, this session object gets closed.
openSession() method helps in opening a new session. You should close this session object once you are done with all the database operations. And also, you should open a new session for each request in a multi-threaded environment.
What is a Hibernate Template class?
When you integrate Spring and Hibernate, Spring ORM provides two helper classes – HibernateDaoSupport and HibernateTemplate. The main reason to use them was to get two things, the Session from Hibernate and Spring Transaction Management. However, from Hibernate 3.0.1, you can use the SessionFactory getCurrentSession() method to get the current session. The major advantage of using this Template class is the exception translation but that can be achieved easily by using @Repository annotation with service classes.
What are the benefits of using Hibernate template?
The following are the benefits of using this Hibernate template class:
Automated Session closing ability.
The interaction with the Hibernate Session is simplified.
Exception handling is automated.
Which are the design patterns that are used in Hibernate framework?
There are a few design patterns used in Hibernate Framework, namely:
Domain Model Pattern: An object model of the domain that incorporates both behavior as well as data.
Data Mapper: A layer of the map that moves data between objects and a database while keeping it independent of each other and the map itself.
Proxy Pattern: It is used for lazy loading.
Factory Pattern: Used in SessionFactory.
Dirty Checking is a mechanism used by Hibernate to determine whether any value of an entity has changed since it was retrieved from the database. This helps Hibernate optimize database queries so that only the fields that have changed are updated. ()update data , 1st we need to load that object with session.get(), this will load that object data into session cache. Within session transaction boudry, if that object field is updated, then hibernate automatically compare this new updated field value to session cache filed value. if it differs, then issue update statement for that field only provided we are making use of dynamicupdate for that entity. if both are same, no update is fired. any update done after session trx is commited, will not take place.
What is meant by Hibernate tuning?
Optimizing the performance of Hibernate applications is known as Hibernate tuning.
The performance tuning strategies for Hibernate are:
SQL Optimization
Session Management
Data Caching
What are the different states of a persistent entity?
It may exist in one of the following 3 states:
Transient: This is not associated with the Session and has no representation in the database.
Persistent: You can make a transient instance persistent by associating it with a Session.
Detached: If you close the Hibernate Session, the persistent instance will become a detached instance.
What is the benefit of Native SQL query support in Hibernate?
Hibernate provides an option to execute Native SQL queries through the use of the SQLQuery object. For normal scenarios, it is however not the recommended approach because you might lose other benefits like Association and Hibernate first-level caching.
Native SQL Query comes handy when you want to execute database-specific queries that are not supported by Hibernate API such query hints or the Connect keyword in Oracle Database.
What is Named SQL Query?
Hibernate provides another important feature called Named Query using which you can define at a central location and use them anywhere in the code.
You can create named queries for both HQL as well as for Native SQL. These Named Queries can be defined in Hibernate mapping files with the help of JPA annotations @NamedQuery and @NamedNativeQuery.
When do you use merge() and update() in Hibernate?
This is one of the tricky Hibernate Interview Questions asked.
update(): If you are sure that the Hibernate Session does not contain an already persistent instance with the same id . merge(): Helps in merging your modifications at any time without considering the state of the Session.
Difference between get() vs load() method in Hibernate?
This is one of the most frequently asked Hibernate Interview Questions. The key difference between the get() and load() method is:
load(): It will throw an exception if an object with an ID passed to them is not found.get(): Will return null.
load(): It can return proxy without hitting the database unless required.get(): It always goes to the database.
So sometimes using load() can be faster than the get() method.
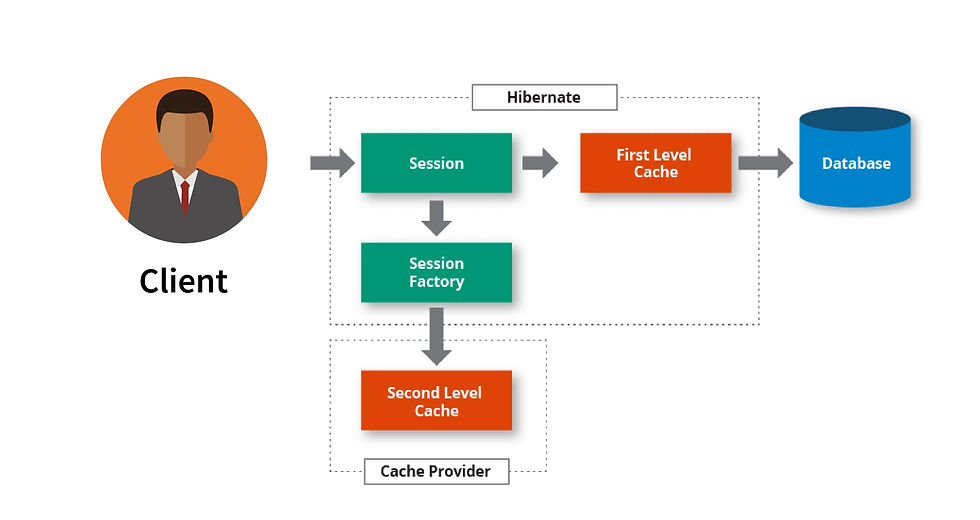
Difference between the first and second level cache in Hibernate?
The first-level cache is maintained at Session level while the second level cache is maintained at a SessionFactory level and is shared by all sessions.
Difference between Session and SessionFactory in Hibernate?
This is yet another popular Hibernate Interview Question asked.
A Session is a single-threaded, short-lived object. It provides the first-level cache.
SessionFactory is immutable and shared by all Session. It also lives until the Hibernate is running. It also provides the second-level cache.
Difference between save() and saveOrUpdate() method of Hibernate?
Even though save() and saveOrUpdate() method is used to store an object into Database, the key difference between them is that save() can only Insert records but saveOrUpdate() can either Insert or Update records.
Difference between sorted and ordered collection in Hibernate?
sorted collection sort the data in JVM’s heap memory using Java’s collection framework sorting methods. The ordered collection is sorted using order by clause in the database itself.
Note: A sorted collection is more suited for small dataset but for a large dataset, it’s better to use ordered collection to avoid
Difference between the transient, persistent and detached state in Hibernate?
Transient state: New objects are created in the Java program but are not associated with any Hibernate Session.
Persistent state: An object which is associated with a Hibernate session is called Persistent object. While an object which was earlier associated with Hibernate session but currently it’s not associate is known as a detached object. You can call save() or persist() method to store those object into the database and bring them into the Persistent state.
Detached state: You can re-attach a detached object to Hibernate sessions by calling either update() or saveOrUpdate() method.
What are the best practices that Hibernate recommends for persistent classes?
All Java classes that will be persisted need a default constructor.
All classes should contain an ID in order to allow easy identification of your objects within Hibernate and the database. This property maps to the primary key column of a database table.
All attributes that will be persisted should be declared private and have getXXX and setXXX methods defined in the JavaBean style.
A central feature of Hibernate, proxies, depends upon the persistent class being either non-final, or the implementation of an interface that declares all public methods.
All classes that do not extend or implement some specialized classes and interfaces required by the EJB framework.
What are the best practices to follow with Hibernate framework?
Always check the primary key field access, if it’s generated at the database layer then you should not have a setter for this.
By default hibernate set the field values directly, without using setters. So if you want Hibernate to use setters, then make sure proper access is defined as @Access(value=AccessType.PROPERTY).
If access type is property, make sure annotations are used with getter methods and not setter methods. Avoid mixing of using annotations on both filed and getter methods.
Use native sql query only when it can’t be done using HQL, such as using the database-specific feature.
If you have to sort the collection, use ordered list rather than sorting it using Collection API.
Use named queries wisely, keep it at a single place for easy debugging. Use them for commonly used queries only. For entity-specific query, you can keep them in the entity bean itself.
For web applications, always try to use JNDI DataSource rather than configuring to create a connection in hibernate.
Avoid Many-to-Many relationships, it can be easily implemented using bidirectional One-to-Many and Many-to-One relationships.
For collections, try to use Lists, maps and sets. Avoid array because you don’t get benefit of lazy loading.
Do not treat exceptions as recoverable, roll back the Transaction and close the Session. If you do not do this, Hibernate cannot guarantee that the in-memory state accurately represents the persistent state.
Prefer DAO pattern for exposing the different methods that can be used with entity bean
Prefer lazy fetching for associations
How do you create an immutable class in hibernate?
Immutable class in hibernate creation could be in the following way. If we are using the XML form of configuration, then a class can be made immutable by markingmutable=false. The default value is true there which indicating that the class was not created by default.
In the case of using annotations, immutable classes in hibernate can also be created by using @Immutable annotation.
What does session.lock() method in hibernate do?
session.lock() method is used to reattach a detached object to the session. session.lock() method does not check for any data synchronization between the database and the object in the persistence context and hence this reattachment might lead to loss of data synchronization.
Types of Hibernate Caching
First Level Cache:
This level is enabled by default.
The first level cache resides in the hibernate session object.
Since it belongs to the session object, the scope of the data stored here will not be available to the entire application as an application can make use of multiple session objects.
First Level Caching

Second Level Cache:
Second level cache resides in the SessionFactory object and due to this, the data is accessible by the entire application.
This is not available by default. It has to be enabled explicitly.
EH (Easy Hibernate) Cache, Swarm Cache, OS Cache, JBoss Cache are some example cache providers.
Second Level Caching
Can you tell the difference between setMaxResults() and setFetchSize() of Query?
setMaxResults() the function works similar to LIMIT in SQL. Here, we set the maximum number of rows that we want to be returned. This method is implemented by all database drivers.
setFetchSize() works for optimizing how Hibernate sends the result to the caller for example: are the results buffered, are they sent in different size chunks, etc. This method is not implemented by all the database drivers.
What happens when the no-args constructor is absent in the Entity bean?
Hibernate framework internally uses Reflection API for creating entity bean instances when get() or load() methods are called. The method Class.newInstance() is used which requires a no-args constructor to be present. When we don't have this constructor in the entity beans, then hibernate fails to instantiate the bean and hence it throws HibernateException.
Can we declare the Entity class final?
No, we should not define the entity class final because hibernate uses proxy classes and objects for lazy loading of data and hits the database only when it is absolutely needed. This is achieved by extending the entity bean. If the entity class (or bean) is made final, then it cant be extended and hence lazy loading can not be supported.
Explain Query Cache
Hibernate framework provides an optional feature called cache region for the queries’ resultset. Additional configurations have to be done in code in order to enable this. The query cache is useful for those queries which are most frequently called with the same parameters. This increases the speed of the data retrieval and greatly improves performance for commonly repetitive queries.
This does not cache the state of actual entities in the result set but it only stores the identifier values and results of the value type. Hence, query cache should be always used in association with second-level cache.
Configuration:
In the hibernate configuration XML file, set the use_query_cache property to true as shown below:
<property name="hibernate.cache.use_query_cache">true</property>
In the code, we need to do the below changes for the query object:
Query query = session.createQuery("from InterviewBitEmployee");
query.setCacheable(true);
query.setCacheRegion("IB_EMP");Can you tell something about the N+1 SELECT problem in Hibernate?
N+1 SELECT problem is due to the result of using lazy loading and on-demand fetching strategy. Let's take an example. If you have an N items list and each item from the list has a dependency on a collection of another object, say bid. In order to find the highest bid for each item while using the lazy loading strategy, hibernate has to first fire 1 query to load all items and then subsequently fire N queries to load big of each item. Hence, hibernate actually ends up executing N+1 queries.
How to solve N+1 SELECT problem in Hibernate?
Some of the strategies followed for solving the N+1 SELECT problem are:
Pre-fetch the records in batches which helps us to reduce the problem of N+1 to (N/K) + 1 where K refers to the size of the batch.
Subselect the fetching strategy
As last resort, try to avoid or disable lazy loading altogether.
What are the concurrency strategies available in hibernate?
Concurrency strategies are the mediators responsible for storing and retrieving items from the cache. While enabling second-level cache, it is the responsibility of the developer to provide what strategy is to be implemented to decide for each persistent class and collection.
Following are the concurrency strategies that are used:
Transactional: This is used in cases of updating data that most likely causes stale data and this prevention is most critical to the application.
Read-Only: This is used when we don't want the data to be modified and can be used for reference data only.
Read-Write: Here, data is mostly read and is used when the prevention of stale data is of critical importance.
Non-strict-Read-Write: Using this strategy will ensure that there wouldn't be any consistency between the database and cache. This strategy can be used when the data can be modified and stale data is not of critical concern.
What is Single Table Strategy?
Single Table Strategy is a hibernate’s strategy for performing inheritance mapping. This strategy is considered to be the best among all the other existing ones. Here, the inheritance data hierarchy is stored in the single table by making use of a discriminator column which determines to what class the record belongs.
For the example defined in the Hibernate Inheritance Mapping question above, if we follow this single table strategy, then all the permanent and contract employees’ details are stored in only one table called InterviewBitEmployee in the database and the employees would be differentiated by making use of discriminator column named employee_type.
Hibernate provides @Inheritance annotation which takes strategy as the parameter. This is used for defining what strategy we would be using. By giving them value, InheritanceType.SINGLE_TABLE signifies that we are using a single table strategy for mapping.
@DiscriminatorColumn is used for specifying what is the discriminator column of the table in the database corresponding to the entity.
@DiscriminatorValue is used for specifying what value differentiates the records of two types.
The code snippet would be like this:
InterviewBitEmployee class:
@Entity
@Table(name = "InterviewBitEmployee")
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn(name = "employee_type")
@NoArgsConstructor
@AllArgsConstructor
public class InterviewBitEmployee {
@Id
@Column(name = "employee_id")
private String employeeId;
private String fullName;
private String email;
}InterviewBitContractEmployee class:
@Entity
@DiscriminatorValue("contract")
@NoArgsConstructor
@AllArgsConstructor
public class InterviewBitContractEmployee extends InterviewBitEmployee {
private LocalDate contractStartDate;
private LocalDate contractEndDate;
private String agencyName;
}InterviewBitPermanentEmployee class:
@Entity
@DiscriminatorValue("permanent")
@NoArgsConstructor
@AllArgsConstructor
public class InterviewBitPermanentEmployee extends InterviewBitEmployee {
private LocalDate workStartDate;
private int numberOfLeaves;
}Can you tell something about Table Per Class Strategy.
Table Per Class Strategy is another type of inheritance mapping strategy where each class in the hierarchy has a corresponding mapping database table. For example, the InterviewBitContractEmployee class details are stored in the interviewbit_contract_employee table and InterviewBitPermanentEmployee class details are stored in interviewbit_permanent_employee tables respectively. As the data is stored in different tables, there will be no need for a discriminator column as done in a single table strategy.
Hibernate provides @Inheritance annotation which takes strategy as the parameter. This is used for defining what strategy we would be using. By giving them value, InheritanceType.TABLE_PER_CLASS, it signifies that we are using a table per class strategy for mapping.
The code snippet will be as shown below:
InterviewBitEmployee class:
@Entity(name = "interviewbit_employee")
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)
@NoArgsConstructor
@AllArgsConstructor
public class InterviewBitEmployee {
@Id
@Column(name = "employee_id")
private String employeeId;
private String fullName;
private String email;
}InterviewBitContractEmployee class:
@Entity(name = "interviewbit_contract_employee")
@Table(name = "interviewbit_contract_employee")
@NoArgsConstructor
@AllArgsConstructor
public class InterviewBitContractEmployee extends InterviewBitEmployee {
private LocalDate contractStartDate;
private LocalDate contractEndDate;
private String agencyName;
}InterviewBitPermanentEmployee class:
@Entity(name = "interviewbit_permanent_employee")
@Table(name = "interviewbit_permanent_employee")
@NoArgsConstructor
@AllArgsConstructor
public class InterviewBitPermanentEmployee extends InterviewBitEmployee {
private LocalDate workStartDate;
private int numberOfLeaves;
}Disadvantages:
This type of strategy offers less performance due to the need for additional joins to get the data.
This strategy is not supported by all JPA providers.
Ordering is tricky in some cases since it is done based on a class and later by the ordering criteria.
Can you tell something about Named SQL Query
A named SQL query is an expression represented in the form of a table. Here, SQL expressions to select/retrieve rows and columns from one or more tables in one or more databases can be specified. This is like using aliases to the queries.
In hibernate, we can make use of @NameQueries and @NameQuery annotations.
@NameQueries annotation is used for defining multiple named queries.
@NameQuery annotation is used for defining a single named query.
Code Snippet: We can define Named Query as shown below
@NamedQueries(
{
@NamedQuery(
name = "findIBEmployeeByFullName",
query = "from InterviewBitEmployee e where e.fullName = :fullName"
)
}
) :fullName refers to the parameter that is programmer defined and can be set using the query.setParameter method while using the named query.
Usage:
TypedQuery query = session.getNamedQuery("findIBEmployeeByFullName");
query.setParameter("fullName","Hibernate");
List<InterviewBitEmployee> ibEmployees = query.getResultList();The getNamedQuery method takes the name of the named query and returns the query instance.
What are the benefits of NamedQuery?
In order to understand the benefits of NamedQuery, let's first understand the disadvantage of HQL and SQL. The main disadvantage of having HQL and SQL scattered across data access objects is that it makes the code unreadable. Hence, as good practice, it is recommended to group all HQL and SQL codes in one place and use only their reference in the actual data access code. In order to achieve this, Hibernate gives us named queries.
A named query is a statically defined query with a predefined unchangeable query string. They are validated when the session factory is created, thus making the application fail fast in case of an error.


Comments