
Compute Services
- Anand Nerurkar
- Jun 28, 2022
- 14 min read

Updated: Jun 29, 2022


Compute Engine
· Predefined machine family: Start running quickly with pre-built and ready-to-go configurations
· Custom machine types: Create VMs with optimal amounts of vCPU and memory, while balancing cost
· Spot machines: Reduce computing costs by up to 91%.
· Confidential computing: Encrypt your most sensitive data while it’s being processed
· Rightsizing recommendations: Optimize resource utilization with automatic recommendations
· Create and manage lifecycle of Virtual Machine (VM) instances
· Load balancing and auto scaling for multiple VM instances Attach storage (& network storage) to your VM instances
· Manage network connectivity and configuration for your VM instances



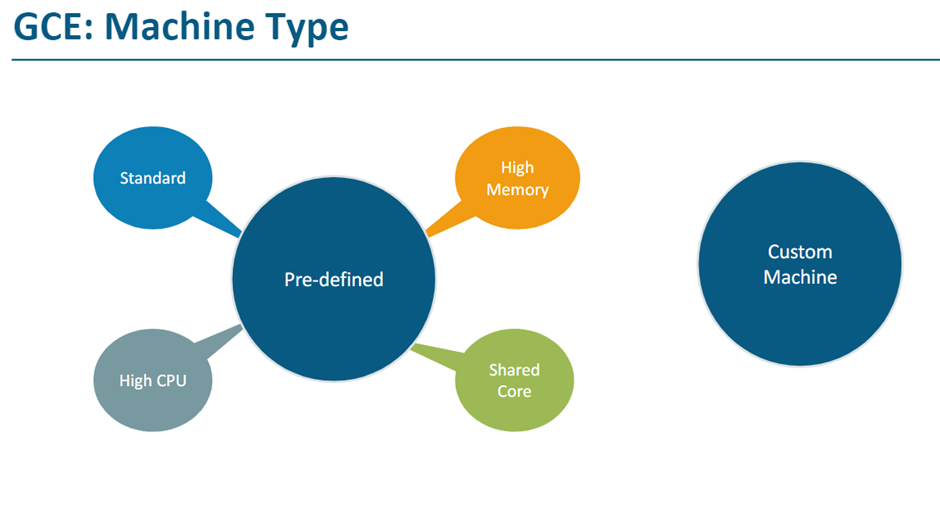






Predefined machine family

Compute Engine instances can run
· public images for Linux and Windows Server that Google provides
· private custom images that you can create or import from existing system.
· Container optimized OS public image.
Compute Engine with startup script to set up HTTP server
Statup script
===
sudo su
apt update apt -y install apache2
sudo service apache2 start
sudo update-rc.d apache2 enable
echo "Hello World" > /var/www/html/index.html
echo "Hello world from $(hostname) $(hostname -I)" > /var/www/html/index.html
VM instance has external ip -public ip and internal ip -private ip.Public ip is dynamic and private ip is static. You can assign static ip to external ip which never change even if you stop/restart VM. Static ip is charged if you not using it.
We normally create VM instance and then ssh into it and then do required library set up for our need. There are no of steps you need to follow up. To reduce this step, we can create instance with
· Start up script
· Instance template
· Custom image
Instance template
· Define machine type, family, image, start up script and other properties
· Used to create similar type of VM instance
· Can be used by managed instance group to create similar type of instaces
· Can not be modified once template define
· To modify, copy the template and then make changes
Custom Image
· Pre Installing OS patches and soware at launch of VM instances
· Can be created from an instance, a persistent disk, a snapshot, another image, or a file in Cloud Storage Can be shared across projects (Recommendation)
· Deprecate old images (& specify replacement image) (Recommendation)
· Hardening an Image - Customize images to your corporate security standards Prefer using Custom Image to Startup script
Instance Group ( Zonal/Regional, Regional mean High Availability)
1. Managed Instance Group- group of vm instances managed as single entity
a. Instance template is mandatory
b. Used to create identical VM instances
c. Support
i. Autoscaling
ii. Autohealing
iii. Load balancing
iv. Managing Releases - support
1. Rolling update
a. Gradual update of instances in an instance group to the new instance template.
b. Specify new template: (OPTIONAL) Specify a template for canary testing
c. Specify how you want the update to be done: When should the update happen?
Start the update immediately (Proactive) or when instance group is resized later(Opportunistic)
d. How should the update happen?
Maximum surge: How many instances are added at any point in time
Maximum unavailable: How many instances can be offline during the update?
2. Rolling Restart/replace:
a. Gradual restart or replace of all instances in the group No change in template BUT replace/restart existing VMs
b. Configure Maximum surge, Maximum unavailable and What you want to do? (Restart/Replace)
3. Canary Deployment
a. Specify new template for canary testing
b. Test new version with a group of instances before releasing it across all instances.
4. Ummanaged instance group
a. Different configuration of VM in the same grou
b. Not recommended
c. Does not support
i. Autoscaling
ii. Autohealing
iii. Load balancing
iv. Releases
Cloud Load Balancing
· distributes user traffic across instances of an application in single region or multiple regions
· Fully distributed, software defined managed service
· Support
o Health check - Route to healthy instances Recover from failures
o Auto Scaling
o Global load balancing with single anycast IP
o supports internal load balancing
o Enables: High Availability Auto Scaling Resiliency

· It supports 1 million+ queries per second with consistent high performance and low latency.
· By using Cloud Load Balancing, you can serve content as close as possible to your users.
Google Cloud offers the following load balancing features:
Single anycast IP address.
With Cloud Load Balancing, a single anycast IP address is the frontend for all of your backend instances in regions around the world.
It provides cross-region load balancing, including automatic multi-region failover, which moves traffic to failover backends if your primary backends become unhealthy.
Cloud Load Balancing reacts instantaneously to changes in users, traffic, network, backend health, and other related conditions.
Software-defined load balancing
Cloud Load Balancing is a fully distributed, software-defined, managed service for all your traffic.
Seamless autoscaling.
Cloud Load Balancing can scale as your users and traffic grow, including easily handling huge, unexpected, and instantaneous spikes by diverting traffic to other regions in the world that can take traffic.
Autoscaling does not require pre-warming: you can scale from zero to full traffic in a matter of seconds.
Layer 4 and Layer 7 load balancing
Use Layer 4-based load balancing to direct traffic based on data from network and transport layer protocols such as TCP, UDP, ESP, GRE, ICMP, and ICMPv6 .
Use Layer 7-based load balancing to add request routing decisions based on attributes, such as the HTTP header and the uniform resource identifier.
External and internal load balancing
You can use external load balancing when your users reach your applications from the internet
internal load balancing when your clients are inside of Google Cloud.
Global and regional load balancing
Distribute your load-balanced resources in single or multiple regions, to terminate connections close to your users, and to meet your high availability requirements.
Advanced feature support.
Cloud Load Balancing supports features such as
IPv6 global load balancing,
WebSockets
user-defined request headers,
protocol forwarding for private VIPs.
It also includes the following integrations:
Integration with Cloud CDN for cached content delivery (supported with the global external HTTP(S) load balancer and the global external HTTP(S) load balancer (classic) only)
Integration with Google Cloud Armor to protect your infrastructure from distributed denial-of-service (DDoS) attacks and other targeted application attacks (supported with the global external HTTP(S) load balancer, the global external HTTP(S) load balancer (classic), the TCP proxy load balancer, and the SSL proxy load balancer)
Cloud Load Balancing - Terminology

· Backend - Group of endpoints that receive traffic from a Google Cloud load balancer (example: instance groups)
· Frontend - Specify an IP address, port and protocol. This IP address is the frontend IP for your clients requests. For SSL, a certificate must also be assigned.
· Host and path rules (For HTTP(S) Load Balancing) - Define rules redirecting the traffic to different backends:
· Based on path - order/view vs payment/view
· Based on Host
· Based on HTTP headers (Authorization header) and methods (POST, GET, etc)
Load Balancing - SSL/TLS Termination/Offloading
· Client to Load Balancer: Over internet HTTPS recommended
· Load Balancer to VM instance: Through Google internal network HTTP is ok. HTTPS is preferred.
· SSL/TLS Termination/Offloading
· Client to Load Balancer: HTTPS/TLS
· Load Balancer to VM instance: HTTP/TCP
Choosing a load balancer
· To determine which Cloud Load Balancing product to use, you must first determine what traffic type your load balancers must handle and whether you need global or regional load balancing, external or internal load balancing, and proxy or pass-through load balancing.
· Then use below decision tree to determine which load balancers are available for your client, protocol, and network configuration.

Google Front Ends (GFEs) are software-defined, distributed systems that are located in Google points of presence (PoPs) and perform global load balancing in conjunction with other systems and control planes.
Andromeda is Google Cloud's software-defined network virtualization stack.
Maglev is a distributed system for Network Load Balancing.
Envoy proxy is an open source edge and service proxy, designed for cloud-native applications.
Load balancer
Underlying technology
Global external HTTP(S) load balancer
GFEs, Envoy
Global external HTTP(S) load balancer (classic)
GFEs
Regional external HTTP(S) load balancer (Preview)
Envoy, Maglev
Internal HTTP(S) load balancer
Andromeda, Envoy
External TCP/UDP network load balancer
Maglev
Internal TCP/UDP load balancer
Andromeda
TCP proxy load balancer
GFEs
SSL proxy load balancer
GFEs
External HTTP(S) Load Balancing use cases
The external HTTP(S) load balancers address many use cases. This page provides some high-level examples.
Three-tier web services
You can use external HTTP(S) Load Balancing to support traditional three-tier web services. The following example shows how you can use three types of Google Cloud load balancers to scale three tiers. At each tier, the load balancer type depends on your traffic type:
· Web tier: Traffic enters from the internet and is load balanced by using an external HTTP(S) load balancer.
· Application tier: The application tier is scaled by using a regional internal HTTP(S) load balancer.
· Database tier: The database tier is scaled by using an internal TCP/UDP load balancer.
The diagram shows how traffic moves through the tiers:
An external HTTP(S) load balancer (the subject of this overview) distributes traffic from the internet to a set of web frontend instance groups in various regions.
These web frontends send the HTTP(S) traffic to a set of regional, internal HTTP(S) load balancers. For the external HTTP(S) load balancer to forward traffic to an internal HTTP(S) load balancer, the external HTTP(S) load balancer must have backend instances with web server software (such as Netscaler or NGINX) configured to forward the traffic to the frontend of the internal HTTP(S) load balancer.
The internal HTTP(S) load balancers distribute the traffic to middleware instance groups.
These middleware instance groups send the traffic to internal TCP/UDP load balancers, which load balance the traffic to data storage clusters.

Layer 7-based routing for internal tiers in a multi-tier app
Multi-region load balancing
When you configure HTTP(S) Load Balancing in Premium Tier, it uses a global external IP address and can intelligently route requests from users to the closest backend instance group or NEG, based on proximity. For example, if you set up instance groups in North America, Europe, and Asia, and attach them to a load balancer's backend service, user requests around the world are automatically sent to the VMs closest to the users, assuming the VMs pass health checks and have enough capacity (defined by the balancing mode). If the closest VMs are all unhealthy, or if the closest instance group is at capacity and another instance group is not at capacity, the load balancer automatically sends requests to the next closest region with capacity.
In Premium Tier, the external HTTP(S) load balancer provides multi-region load balancing, using multiple backend services, each with backend instance groups or NEGs in multiple regions.

Representation of multi-region load balancing
Workloads with jurisdictional compliance
Some workloads with regulatory or compliance requirements require that network configurations and traffic termination reside in a specific region. For these workloads, a regional external HTTP(S) load balancer is often the preferred option to provide the jurisdictional controls these workloads require.
Load Balancing Across MIGS in multiple region
Regional MIG can distribute instances in different zones of a single region
Create multiple Regional MIGs in different regions (in the same project)
HTTP(S) Load Balancing can distribute load to the multiple MIGs behind a single external IP address
User requests are redirected to the nearest region (Low latency)
Load balancing sends traffic to healthy instances: If health check fails instances are restarted: (REMEMBER) Ensure that health check from load balancer can reach the instances in an instance group (Firewall rules) If all backends within a region are unhealthy, traffic is distributed to healthy backends in other regions. Can contain preemptible instances as well!
Backend Service - Group of backends or a bucket
Backend - A Managed Instance Group
URL Maps - Route requests to backend services or backend buckets
URL /service-a maps to Backend Service A
URL /service-b maps to Backend Service B (Remember)
Each Backend Service can have multiple backends in multiple regions

HTTPS Load Balancing
Usecase 1 : Multiregional Microservices
· Backend Services
· One Backend Service for the Microservice
· Backends
· Multiple backends for each microservice MIG in each region
· URL Maps URL /service-a maps to the microservice Backend Service
· Global routing: Route user to nearest instance (nearest regional MIG) Needs Networking Premium Tier: As in STANDARD Tier: Forwarding rule and its external IP address are regional All backends for a backend service must be in the same region as the forwarding rule

2 Multiple Microservices
· Backend Services
· One Backend Service for each the Microservice
· Backends
· Each microservice can have multiple backend MIGs in different regions In the example, we see one backend per microservice
· URL Maps
· URL /service-a => Microservice A Backend Service
· URL /service-b => Microservice B Backend Service

3. Microservices version
· Backend Services
· A Backend Service for each Microservice version
· Backends
· Each microservice version can have multiple backend MIGs in different regions In the example, we see one backend per microservice version
· URL Maps
· /service-a/v1 => Microservice A V1 Backend Service
· /service-a/v2 => Microservice A V2 Backend Service
· /service-b => Microservice B Backend Service
Flexible Architecture: With HTTP(S) load balancing, route global requests across multiple versions of multiple microservices.
App Engine
· App Engine is a fully managed, serverless platform for developing and hosting web applications at scale.
· support several popular languages, libraries, and frameworks to develop your apps
o Java
o Node JS
o Python
o .Net
o Go
o Ruby
App Engine take care of provisioning servers and scaling your app instances based on demand.
Components of an application Your App Engine app is created under your Google Cloud project when you create an application resource.
The App Engine application is a top-level container that includes the service, version, and instance resources that make up your app.
When you create your App Engine app, all your resources are created in the region that you choose, including your app code along with a collection of settings, credentials, and your app's metadata.
Each App Engine application includes at least one service, the default service, which can hold many versions, depending on your app's billing status. For more information, see Limits below. The following diagram illustrates the hierarchy of an App Engine app running with multiple services.

In this diagram, the app has two services that contain multiple versions, and two of those versions are actively running on multiple instances:
Other Google Cloud services, for example Datastore, are shared across your App Engine app. For more information, see Structuring web services.
Services
Use services in App Engine to factor your large apps into logical components that can securely share App Engine features and communicate with one another. Generally, your App Engine services behave like microservices. Therefore, you can run your whole app in a single service or you can design and deploy multiple services to run as a set of microservices.
For example, an app that handles your customer requests might include separate services that each handle different tasks, such as:
API requests from mobile devices
Internal, administration-type requests
Backend processing such as billing pipelines and data analysis
Each service in App Engine consists of the source code from your app and the corresponding App Engine configuration files. The set of files that you deploy to a service represent a single version of that service and each time that you deploy to that service, you are creating additional versions within that same service. Versions Having multiple versions of your app within each service allows you to quickly switch between different versions of that app for rollbacks, testing, or other temporary events. You can route traffic to one or more specific versions of your app by migrating or splitting traffic. Instances The versions within your services run on one or more instances. By default, App Engine scales your app to match the load. Your apps will scale up the number of instances that are running to provide consistent performance, or scale down to minimize idle instances and reduces costs. For more information about instances, see How Instances are Managed. Application requests Each of your app's services and each of the versions within those services must have a unique name. You can then use those unique names to target and route traffic to specific resources using URLs, for example: https://VERSION-dot-SERVICE-dot-PROJECT_ID.REGION_ID.r.appspot.com Note that the combined length of VERSION-dot-SERVICE-dot-PROJECT_ID, where VERSION is the name of your version, SERVICE is the name of your service, and PROJECT_ID is your project ID, cannot be longer than 63 characters and cannot start or end with a hyphen. If the combined length is longer than 63 characters, you might see Error DNS address could not be found. Incoming user requests are routed to the services or versions that are configured to handle traffic. You can also target and route requests to specific services and versions. For more information, see Communicating Between Services. Logging application requests When your application handles a request, it can also write its own logging messages to stdout and stderr. For details about your app's logs, see Writing Application Logs. Limits The maximum number of services and versions that you can deploy depends on your app's pricing: LimitFree appPaid appMaximum services per app5105Maximum versions per app15210 There is also a limit to the number of instances for each service with basic or manual scaling: Maximum instances per manual/basic scaling versionFree appPaid app USPaid app EU2025 (200 for us-central)25 There is also a limit to the number of characters in the URL of your application. DescriptionLimitMaximum characters in Project URL for VERSION-dot-SERVICE-dot-PROJECT_ID URL63










Cloud Functions
· Cloud Functions is a scalable, pay-as-you-go functions as a service (FaaS) product to help you build and connect event driven services with simple, single purpose code.
· Run your code in the cloud with no servers or containers to manage.



USE CASE
1. Integration with third-party services and APIs
Use Cloud Functions to surface your own microservices via HTTP APIs or integrate with third-party services that offer webhook integrations to quickly extend your application with powerful capabilities such as sending a confirmation email after a successful Stripe payment or responding to Twilio text message events.

2. Serverless mobile back ends
Use Cloud Functions directly from Firebase to extend your application functionality without spinning up a server. Run your code in response to user actions, analytics, and authentication events to keep your users engaged with event-based notifications and offload CPU- and networking-intensive tasks to Google Cloud.
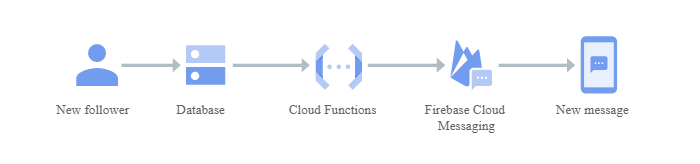
3. Serverless IoT back ends
Use Cloud Functions with Cloud IoT Core and other fully managed services to build back ends for Internet of Things (IoT) device telemetry data collection, real-time processing, and analysis. Cloud Functions allows you to apply custom logic to each event as it arrives.

4. Real-time file processing
Execute your code in response to changes in data. Cloud Functions can respond to events from Google Cloud services such as Cloud Storage, Pub/Sub, and Cloud Firestore to process files immediately after upload and generate thumbnails from image uploads, process logs, validate content, transcode videos, validate, aggregate, and filter data in real time.

5. Real-time stream processing
Use Cloud Functions to respond to events from Pub/Sub to process, transform, and enrich streaming data in transaction processing, click-stream analysis, application activity tracking, IoT device telemetry, social media analysis, and other types of applications.

Cloud Run
Develop and deploy highly scalable containerized applications using your favorite language (Go, Python, Java, Node.js, .NET, and more) on a fully managed serverless platform. All Google Cloud customers get 2 million requests per month completely free of charge.
Key features
· Any language, any library, any binary
o Use the programming language of your choice, any language or operating system libraries, or even bring your own binaries.
· Leverage container workflows and standards
Containers have become a standard to package and deploy code and its dependencies. Cloud Run pairs great with the container ecosystem: Cloud Build, Cloud Code, Artifact Registry, and Docker.
· Pay‐per‐use
Only pay when your code is running, billed to the nearest 100 milliseconds.






USE CASE
Web services: Websites
Build your website using a mature technology stack such as nginx, ExpressJS, and django, access your SQL database on Cloud SQL, and render dynamic HTML pages.

USE CASE
Web services: REST APIs backend
Modern mobile apps commonly rely on RESTful backend APIs to provide current views of application data and separation for frontend and backend development teams. API services running on Cloud Run allow developers to persist data reliably on managed databases such as Cloud SQL or Firestore (NoSQL). Logging in to Cloud Run grants users access to app‐resource data stored in Cloud Databases.

USE CASE Web services: Back‐office administration Back‐office administration often requires documents, spreadsheets, and other custom integrations, and running a vendor‐supplied web application. Hosting the containerized internal web application on Cloud Run means it is always ready and you are only billed when it is used.

USE CASE
Data processing: Lightweight data transformation
Build Cloud Run data processing applications that transform lightweight data as it arrives and store it as structured data. Transformations can be triggered from Google Cloud sources.
When a .csv file is created, an event is fired and delivered to a Cloud Run service. Data is then extracted, structured, and stored in a BigQuery table.

USE CASE Automation: Scheduled document generation Schedule a monthly job with Cloud Scheduler to generate invoices using a Cloud Run service. Because containers containing custom binaries can be deployed to Cloud Run, it is able to run in a PDF generation tool like LibreOffice in a serverless way, which means only paying when you are generating invoices.

USE CASE Automation: Business workflow with webhooks Connect your operations together with an event‐driven approach. Cloud Run scales on demand while implementing a webhook target, pushing events in the form of requests and only charging you when you receive and process the event. React to events from GitHub or Slack, or send webhooks when a purchase is made, a job is ready, or an alert is fired with a service that can react on a just‐in‐time basis to trigger a microservice in your infrastructure.

Google Cloud VMware Engine
Easily lift and shift your VMware-based applications to Google Cloud without changes to your apps, tools, or processes. Includes all the hardware and VMware licenses to run in a dedicated VMware SDDC in Google Cloud.





Comments